
AIは、攻撃される。AIは、騙される。AIは、悪用される。
どれだけ高精度なAIを作っても、それを壊そうとする人間がいます。どれだけ安全に設計されたAIでも、想定外の使い方をする人間がいます。
この章では、AIをめぐる「悪意ある行為」と、それへの対処法を見ていきます。
AIの安全性とは何か
AIの安全性とは、AIシステムが意図した通りに動作し、意図しない害を引き起こさないことを指します。
安全性の問題は二つの方向から生じます。
一つは意図しない失敗——AIが設計者の意図に反して誤った判断を下すこと。
もう一つは意図的な攻撃——悪意を持った第三者がAIを攻撃・操作すること。
自動運転AIが障害物を認識できずに事故を起こす、医療診断AIが誤った診断を下す——これらは意図しない失敗の例です。一方、AIを騙して誤った判断をさせる攻撃は、意図的な攻撃にあたります。
Adversarial Attackとは何か
Adversarial Attack(アドバーサリアル・アタック:敵対的攻撃)とは、AIに誤った判断をさせるために、入力データに人間には気づかないほどの微小な変化を加える攻撃手法です。
その変化を加えられたデータをAdversarial Examples(敵対的サンプル)と呼びます。
具体的な例で考えてみましょう。
画像認識AIに「パンダ」の写真を見せると、正しく「パンダ」と識別します。しかしその写真に、人間の目にはまったく見えないほどのわずかなノイズを加えると——AIは突然「テナガザル」と誤識別してしまいます。
画像は人間の目にはほぼ同じに見えるのに、AIの判断は180度変わってしまうのです。
なぜこんなことが起きるのでしょうか。
AIは画像の「人間が見ている特徴」ではなく、「統計的なパターン」を学んでいるからです。そのパターンに微妙な変化を加えることで、AIを騙せてしまうのです。
Adversarial Attackが特に危険なのは、現実への応用です。
自動運転AIに対して、道路標識に微小なステッカーを貼ることで「一時停止」を「制限速度なし」と誤認識させる実験が行われています。顔認識システムに対して、特殊なメイクや眼鏡をかけることで認識を回避する手法も研究されています。
データ汚染・モデル汚染とは何か
データ汚染(Data Poisoning)とは、AIの学習データに悪意ある情報を混入させることで、学習済みモデルの動作を意図的に歪める攻撃です。
たとえばスパムフィルターのAIを学習させるデータに、悪意ある攻撃者が「これはスパムではない」という誤ったラベルを大量に混入させると——AIはスパムをスパムと認識できなくなります。
「汚染された食材で料理を作ると、料理全体が台無しになる」——それと同じことがAIの学習で起きるのです。
モデル汚染(Model Poisoning)は、学習データではなくモデルそのものを攻撃する手法です。
連合学習(複数の組織がデータを持ち寄って共同でモデルを学習させる仕組み)において、参加者の一人が悪意ある更新情報を送り込むことで、モデル全体を汚染することができます。
Adversarial Attack・データ汚染・モデル汚染の関係
三つの攻撃手法は混同されやすいですが、「どの段階で」「どこを」攻撃するかで整理できます。
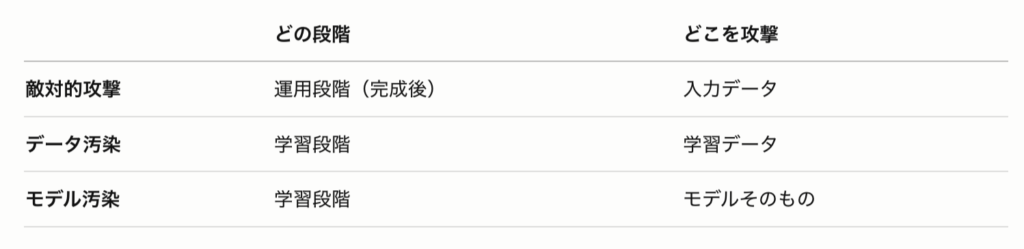
敵対的攻撃は完成したAIを使う段階で攻撃します。動いているAIに細工した入力を与えて、誤った判断をさせる——「完成したAIを騙す」攻撃です。
データ汚染とモデル汚染はどちらも学習段階での攻撃ですが、攻撃する場所が違います。
データ汚染は学習データに悪意ある情報を混入させて学習自体を歪める——「育てている段階のAIを歪める」攻撃です。
モデル汚染はモデルそのものを攻撃します。特に連合学習において、複数の組織が学習結果を持ち寄るとき、一つの組織が悪意ある更新情報を送り込むことでモデル全体を歪めることができます。
データ窃取・モデル窃取とは何か
データ窃取とは、AIの学習に使われたデータを不正に取得する攻撃です。
AIモデルに大量の質問を投げかけることで、モデルが学習したデータの内容を推測・復元できることがあります。
医療データで学習したAIから、患者の個人情報が漏洩するリスクがあります。
モデル窃取(Model Extraction)とは、AIモデルそのものを不正に複製する攻撃です。
公開されているAIサービスに大量の入力を与えて出力を収集し、その入出力のパターンから元のモデルを模倣した「コピーモデル」を作ることができます。
開発に多大なコストをかけたAIモデルが、攻撃によってコピーされてしまうリスクです。
セキュリティ・バイ・デザイン
プライバシー・バイ・デザインと同様に、セキュリティ・バイ・デザイン(Security by Design)という考え方があります。
「後からセキュリティ対策を追加する」のではなく、「最初からセキュリティを組み込んで設計する」という発想です。
AIシステムを開発する段階から、Adversarial Attackへの耐性、データ汚染への対策、不正アクセスへの防御を設計に組み込むことが求められます。
ディープフェイク
ディープフェイク(Deepfake)とは、AIを使って人物の顔・声・動作を別の人物のものに置き換えた、本物と見分けがつかない偽の映像・音声のことです。
「Deep Learning(深層学習)」と「Fake(偽物)」を組み合わせた造語です。
ディープフェイクが危険な理由は、その「本物らしさ」にあります。有名人が言っていない発言をしているように見せる偽動画、実在の人物の顔を使ったポルノグラフィ、政治家が不正を行っているように見せる偽映像——これらは社会的な信頼を根底から揺さぶります。
「自分の目で見たものを信じる」——人間の根本的な認識の習慣を、ディープフェイクは武器として使います。
声優さんの声をAIで生成する問題と同じく、本人の同意なく顔や声を使われるというプライバシーの問題も深刻です。
ディープフェイクへの対処として——ディープフェイク検出AIの開発、デジタルウォーターマーク(画像・動画に見えない形で出所情報を埋め込む技術)の活用、メディアリテラシー教育——といった取り組みが進んでいます。
フェイクニュース
フェイクニュースとは、意図的に作られた虚偽の情報・ニュースのことです。
AIの登場によって、フェイクニュースの生成・拡散のスピードと規模が劇的に変わりました。
生成AIを使えば、もっともらしい偽のニュース記事を大量に、瞬時に作ることができます。ディープフェイクの映像と組み合わせれば、「実際に起きていない出来事」をリアルに見せることができます。SNSのアルゴリズムは感情を刺激するコンテンツを優先して表示するため、フェイクニュースは本物のニュースより速く、広く拡散することがあります。
フェイクニュースは次のページで見る「民主主義」の問題とも深く絡み合っています。「何が真実か」を見極める力——メディアリテラシー——が、AIの時代にますます重要になっています。
まとめ
Adversarial Attack(敵対的攻撃) → AIに誤った判断をさせるために、入力データに人間には気づかないほどの微小な変化を加える攻撃手法
Adversarial Examples(敵対的サンプル) → Adversarial Attackによって微小な変化を加えられたデータ。人間には元のデータと区別がつかないが、AIを誤認識させる
データ汚染 → AIの学習データに悪意ある情報を混入させることで、学習済みモデルの動作を歪める攻撃
モデル汚染 → 学習データではなくモデルそのものを攻撃する手法。連合学習において悪意ある更新情報を送り込むことで起きる
データ窃取 → AIの学習に使われたデータを不正に取得する攻撃
モデル窃取 → AIサービスに大量の入力を与えて出力を収集し、元のモデルを模倣したコピーモデルを作る攻撃
セキュリティ・バイ・デザイン → セキュリティ対策を後から追加するのではなく、最初から設計に組み込む考え方
ディープフェイク → AIを使って人物の顔・声・動作を別の人物のものに置き換えた、本物と見分けがつかない偽の映像・音声
フェイクニュース → 意図的に作られた虚偽の情報・ニュース。生成AIの登場によって生成・拡散の規模が劇的に変化した
next ▶ 透明性