
事前学習済みモデルは、膨大な知識を持つ「何でも知っている人」です。
しかし「何でも知っている人」が、必ずしも特定の仕事の「専門家」であるとは限りません。
医療の現場では医療の言葉で、法律の世界では法律の論理で、料理のレシピサイトでは料理の文脈で——特定の領域に特化した能力が求められる場面では、汎用的な知識だけでは不十分なことがあります。
事前学習で「広く学んだAI」を、特定の仕事の「専門家」へと育て上げる——それがファインチューニングの役割です。しかしその過程には、一つの落とし穴が潜んでいます。
ファインチューニング
ファインチューニング(Fine-tuning) とは、事前学習済みモデルを土台にして、特定のタスクに特化したデータで追加学習させる手法です。
「微調整」という意味を持つその名の通り、モデル全体を一から作り直すのではなく、すでに持っている知識を特定の目的に合わせて「磨き直す」イメージです。
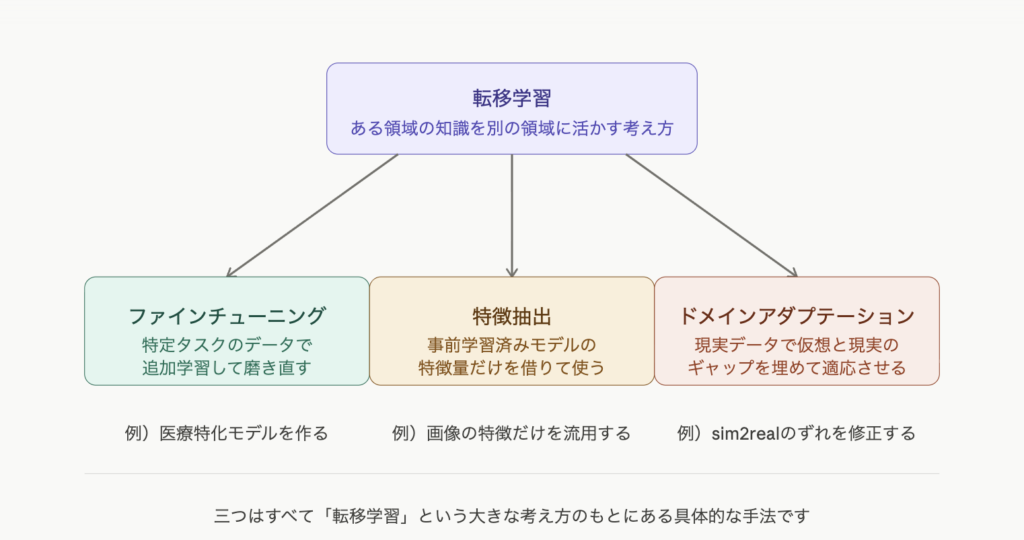
ここで一つ、前のページで登場した「転移学習」との関係を整理しておきましょう。転移学習とファインチューニングは混同されやすいですが、こう考えると区別しやすくなります。
転移学習 → 「ある領域で学んだ知識を、別の領域に活かす」という発想・アプローチ全体
ファインチューニング → その転移学習を実現するための具体的な手法の一つ
転移学習が「フランス料理の経験を和食に活かす」という発想だとすれば、ファインチューニングは「そのために和食の名店で修業し直す」という具体的な行動です。転移学習という大きな傘の下に、ファインチューニングがある——そんな関係です。
具体的な場面を見てみましょう。膨大なテキストで事前学習した言語モデルがあるとします。このモデルに、医療論文や診療記録などの医療専門データを使って追加学習させると、医療用語を正確に理解し、医療的な文脈に沿った回答ができる医療特化モデルに育ちます。同じモデルに法律文書を学ばせれば法律特化モデルに、料理レシピを学ばせれば料理特化モデルになる——事前学習という共通の土台の上に、ファインチューニングによって専門性を積み上げていくのです。
破壊的忘却
しかし、ファインチューニングには厄介な落とし穴があります。それが破壊的忘却(Catastrophic Forgetting)です。
破壊的忘却とは、新しいタスクを学習する過程で、それまでに学んでいた知識が上書きされて失われてしまう現象です。
医療データでファインチューニングしたモデルが、医療の専門知識を得る一方で、事前学習で身につけていた一般的な言語能力や幅広い知識を失ってしまう——そんなことが起きます。
人間にたとえるなら、こんな場面を想像してみてください。
長年フランス語を勉強してきた人が、スペイン語の猛特訓を始めたとき、似ている言語構造が混乱を招き、以前は流暢に話せたフランス語がぎこちなくなってしまう——そんな感覚に近いかもしれません。新しいことを覚えようとするほど、古いことが薄れていく。
AIにとってこれは深刻な問題です。専門家として磨かれるほど、かつての汎用的な知識が失われていく。専門性と汎用性のトレードオフ——この緊張関係は、人間の学びの在り方とも、どこか通じるものがあります。
この問題への対処法として、いくつかの工夫が研究されています。
新しいタスクを学びながら古いタスクのデータも混ぜて学習し続ける方法、モデルの重要な部分は変えずに一部だけを更新する方法——完全な解決策はまだなく、現在も活発に研究が続いている分野です。